

Problem
Ruby on Rails and Searchkick have allowed us to rapidly build applications with powerful search capabilities on top of vast amounts of data. Searchkick is a Ruby gem that integrates with Elasticsearch or OpenSearch, offering advanced search capabilities and enabling complex data queries efficiently. Re-indexing Searchkick models is essential to maintain search accuracy and performance, but the current solutions lead to data inconsistency during the process. This happens because writes and updates made while re-indexing are not reflected in the new index, causing missing or outdated data after the re-index completes. This is a critical issue for high-traffic applications with frequent data changes.
Solution
This article proposes a solution to achieve zero downtime re-indexing with Searchkick by overriding its index jobs. This allows us to duplicate any operation (create, update, delete) happening during re-indexing to both the current and new index, ensuring data consistency. The solution leverages:
- Ruby on Rails extensions to modify
Searchkickbehavior - Redis to store re-indexing state and flags
- Index aliases for seamless transition between old and new indexes
Introduction
At Woflow, we are riding the Ruby on Rails and Searchkick express train, and it has allowed us to rapidly build applications capable of managing vast amounts of data. Using this dynamic duo, we are able to run fast full-text searches using dozens of filters on indexes with millions of entries.
Re-indexing is essential for maintaining search accuracy, data structure, and performance over time. When using Searchkick you need to re-index when:
- install or upgrade
searchkickgem - change the
search_datamethod - change the
searchkickmethod
This article is meant for software engineers, architects, developers or enthusiasts using Ruby on Rails with Searchkick in production environments. We'll explore an efficient and reliable method for re-indexing your Searchkick database while maintaining uninterrupted search functionality and real-time result updates. Our approach ensures seamless user experience during the re-indexing process, critical for high-traffic applications.
Naive solution
To tackle the re-index issue, most of us would start by scouring the internet. You'd think that with two battle-tested technologies, you'd stumble upon several reliable foolproof solutions, right? Well, not quite. Most of the solutions we found online for re-indexing Searchkick models have a major snag. They solve the problem of allowing users to search for data while the re-index is happening, but if the user writes data, it will eventually be lost.
Let's first take a peek at the code for the most common solution we stumbled across in the wild:
require 'sidekiq/api'
module ModelReindexer
def self.reindex_model(model, promote_and_clean = true)
puts "ModelReindexer started for model: #{model.name}"
# Async here will force jobs to be created in Sidekiq
index = model.reindex(async: true, refresh_interval: '30s')
puts "All jobs queued in index: #{index[:index_name]}"
loop do
# Check the reindex status using Searchkick
status = Searchkick.reindex_status(index[:index_name])
puts "Reindex batches left: #{status[:batches_left]}"
# Check every 5 seconds
sleep 5
break if status[:completed]
end
puts 'Reindex complete. Promoting...'
model.search_index.promote(index[:index_name], update_refresh_interval: true)
puts "Reindex of #{model.name} complete."
if promote_and_clean
puts 'Cleaning old indices'
model.search_index.clean_indices
end
end
end
Over large datasets, these re-index operations can take several minutes. In our case, we have more than 10 indexes with 2-10 million documents in each, and that can take up to 1 hour to fully re-index. With that delay, one can run into a major roadblock: how to keep the search features running smoothly while running re-index without causing downtime or data loss. For our search features to continue working flawlessly, during the re-index, users will have to be able to continue to search and write data, of course.
This discrepancy creates a significant data consistency problem. By the time the re-indexing completes and the new index is promoted, it's already out of date. Any records that were created, updated, or deleted in the original index during the process are not captured in the new index. This can lead to missing data, outdated information, or "phantom" records that no longer exist in the database but persist in the search index. In high-traffic applications or those with frequent data changes, this inconsistency can be substantial, potentially affecting the accuracy and reliability of search results immediately after the re-index operation completes.
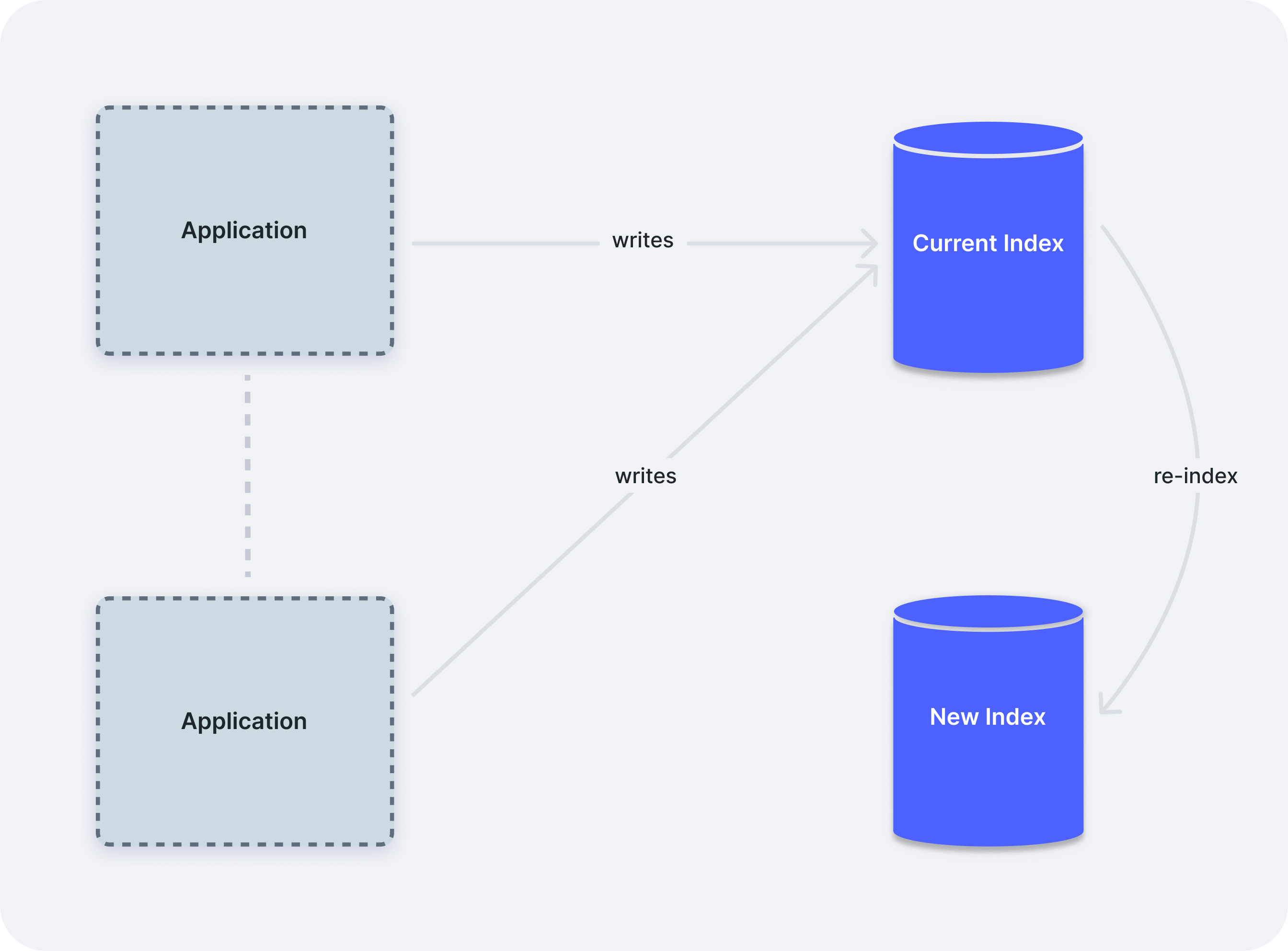
The fix: Double-write data while re-indexing
Ankane, the creator of Searchkick, talks about this problem in this very cohesive article.
Even though Searchkick Pro is not available anymore, the solution is still described in the blog post. It is simple enough: every time we are about to run an operation in the current index, we queue the same operation for the new index. This Job queue is handled by Sidekiq.
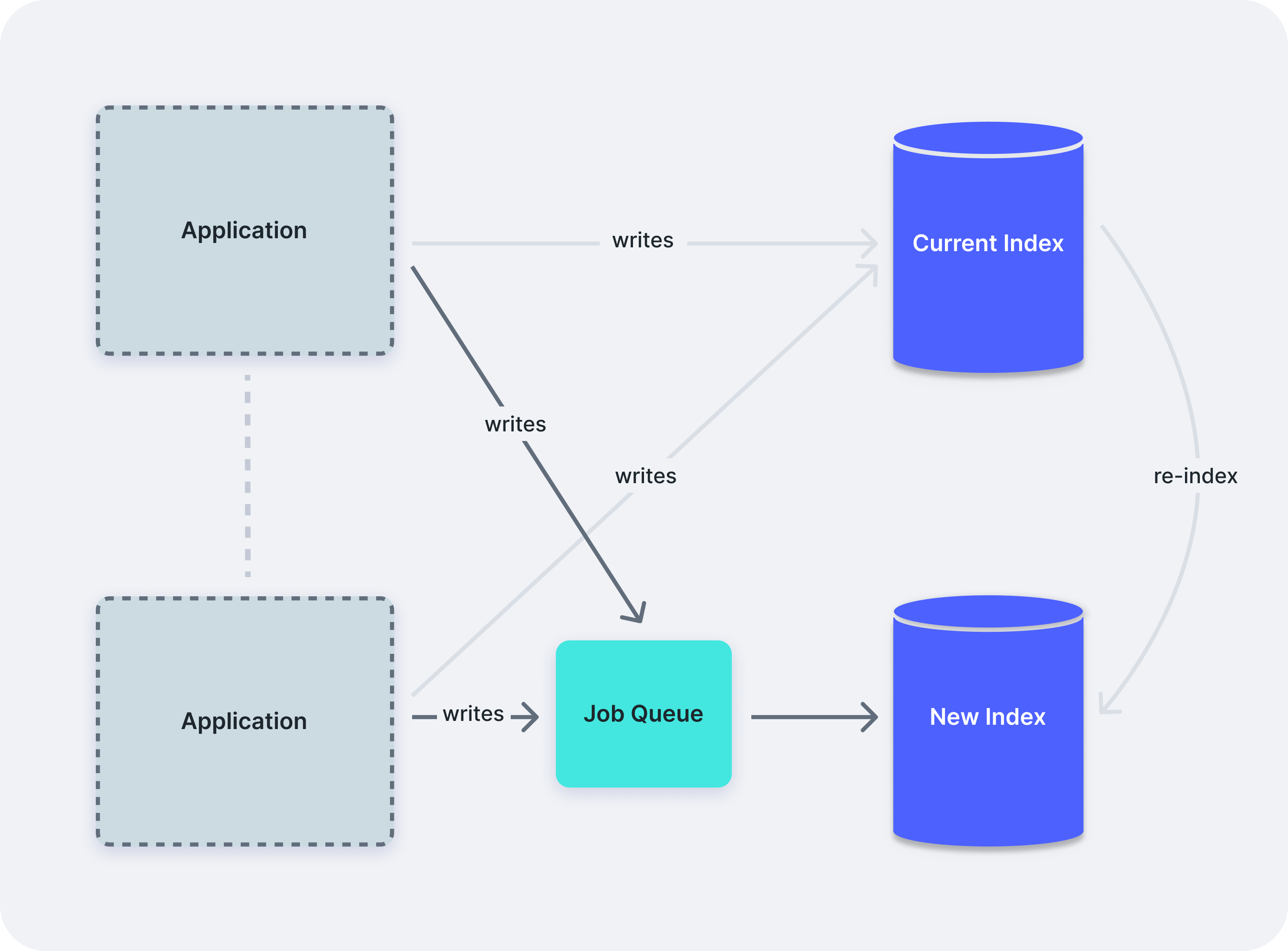
Implementing the full solution
To implement this solution, we are going to extend Searchkick's functionality by overriding its index jobs. This approach allows us to intercept and modify the behavior of these jobs, ensuring that any changes made during the re-indexing process are captured in both the current and new indexes. By doing so, we can maintain data consistency and achieve zero downtime during the re-indexing operation.
Extending Searchkick
The main idea is to override all the index jobs found in the Searchkick module. One great way to do that is by leveraging Ruby on Rails extensions. We should be careful about this though, here is the warning.
💡 Though Ruby allows you to reopen classes, you shouldn't abuse that feature. In particular, avoid changing existing methods, especially in the Ruby core or standard library. If you change the behavior of a method, your application might stop working properly.
If you decide to add a new method, make sure you are using an unique name. Otherwise, if you are using a Gem which defines a method with the same name, something might not work as expected.
Be careful when you modify existing classes. Consider using Inheritance or Composition.
But oh well, we need to improve Searchkick, so we created an extension to enhance this module. We are going to need to override certain job classes provided by it, such as BulkReindexJob and ProcessBatchJob, for example. We can find all the background jobs in this part of the Searchkick source code (gotta love open source ❤️).
Leveraging Redis for State Management
Redis plays a crucial role in maintaining the state of re-indexing processes in this extension. It stores control flags and the new index name, enabling us to track and duplicate the operations to the new index, ensuring we maintain data integrity.
Utilizing Index Aliases
Searchkick internally uses index aliases for the re-index process, which allows seamless transition between old and new indexes without changing the application's index references. This mechanism is crucial in ensuring zero downtime, as it enables the application to switch to the new index once re-indexing is complete, without any interruptions. You can read more about this topic in this Elasticsearch documentation.
Implementing the Rails Extension
So, without further ado, we started implementing the extension. The idea is to prepend all relevant job classes with a new module ReindexCheck. This module will override the perform method in a way that will intercept job execution, check re-indexing status, and ensure data consistency by writing to both indexes during the process if necessary. Here’s a simplified implementation of this idea:
module Searchkick
module ReindexCheck
def perform(*args, **options)
job_type = self.class.name.demodulize
class_name, index_name, record_ids = extract_job_details(job_type, args, options)
new_index_name = Searchkick.get_new_index_name(class_name)
if reindexing?(class_name) && index_name != new_index_name
spawn_job_for_new_index(job_type, args, options, class_name, new_index_name, record_ids)
end
super(*args, **options)
end
end
JOBS_TO_OVERRIDE = [BulkReindexJob, ProcessBatchJob, ProcessQueueJob, ReindexV2Job]
JOBS_TO_OVERRIDE.each do |job_class|
job_class.class_eval do
prepend Searchkick::ReindexCheck
end
end
# .... for simplicity some methods are omitted here, you can find their full implementation at the end of the article
end
💡 One super important step after implementing this extension is to write solid unit tests. They will make sure you update your extension whenever Searchkick's source code evolves, especially if the signatures of these jobs change.
Updating the solution to manage the Re-indexing Process
At Woflow, we decided to make a rake task for whenever we need to fully re-index a model. In order to expose flags and the new index name to Redis, so our extensions can access that needed information. Here’s a simplified version of our rake task:
namespace :searchkick do
task :async_reindex, [:model] => :environment do |_task, args|
model_name = args[:model]
model_class = {
'Entry' => Entry,
'Brand' => Brand,
'Job' => Job
}[model_name]
raise "Invalid model name: #{model_name}" unless model_class
puts "Reindexing #{model_name}..."
index = model_class.reindex(async: true, refresh_interval: '30s')
Searchkick.flag_start_reindex(model_name, index[:index_name])
loop do
# Check the reindex status using Searchkick
status = Searchkick.reindex_status(index[:index_name])
puts "Reindex batches left: #{status[:batches_left]}"
# Check every 15 seconds
sleep 15
break if status[:completed]
end
model_class.search_index.promote(index[:index_name])
Searchkick.flag_end_reindex(model_name)
puts "#{model_name} reindexing complete."
end
end
In this rake task, we call the reindex method with async true, flag the start of the index and the new index name in Redis. Then we wait for the re-index batches to reach 0. When it does, we promote the new index (internally it will update the Opensearch/ ElasticSearch aliases) and then we clear the index flag from Redis.
Conclusion
The solution detailed in this post provides a practical approach to achieving reliable zero downtime re-indexing with Searchkick. While it may not be perfect, it effectively addresses the data consistency issues that can arise during re-indexing. To ensure its reliability, it's crucial to:
- Implement comprehensive unit tests to protect against future changes in
Searchkick's source code - Set up proper logging mechanisms to monitor the re-indexing process
- Regularly review and update the implementation as needed, especially after Searchkick updates
By following these steps and understanding the intricacies of the solution, you can maintain a robust and efficient search functionality in your Ruby on Rails application, even when dealing with large datasets and frequent updates. Happy coding and good luck. 👏 🙇 🎬
PS: Obfuscated implementations
Disclaimer: The generic methods for extracting jobs details and spawning secondary jobs were omited from the top text to avoid extra noise. They are noisy but simple to understand and can be found HERE.



.jpeg)


